Acceptance Test Anatomy
关于验收测试的剖析
原文地址:https://gojko.net/2010/06/16/anatomy-of-a-good-acceptance-test/
作者:Gojko Adzic
敏捷验收测试的长期收益来自于活文档——它是一份系统功能的描述文档,可靠,易于访问,并且比代码更容易阅读和理解。为了能够成为有效的、活的规范说明,验收测试必须以这样一种方式写作——能够让他人在几个月甚至几年以后,轻易地明白他们在做什么,为什么做以及具体的描述是什么。这里有一些简单的启发式方法,可以帮助你度量和改进测试,使其更好地成为一份活的规范说明。
需要思考的五个最重要的点是:
- 它必须是自解释的 (self explanatory)
- 它必须要聚焦
- 它必须是一个具体描述,而不是脚本
- 它必须使用领域语言
- 它必须是关于业务功能,而不是软件设计
这里有一个很好的例子:
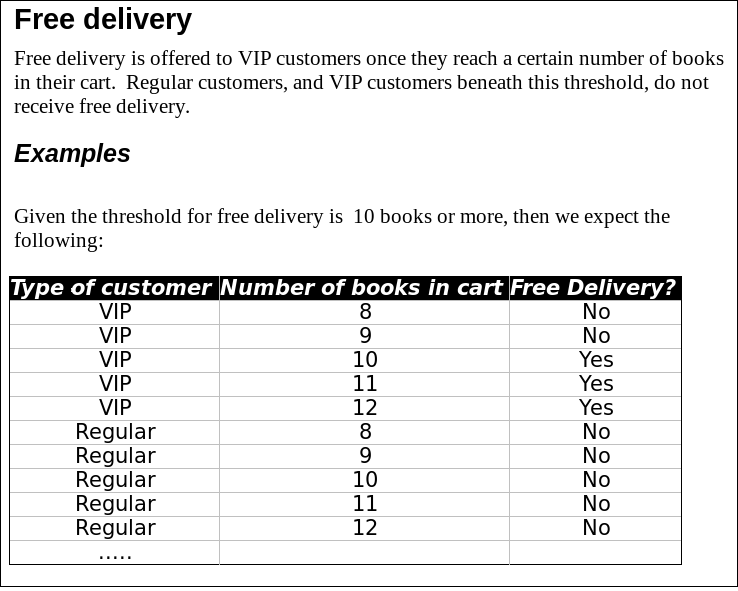
它具备了上边列出的所有要素。每当我在工作坊向人们展示这个例子时,我都不需要解释一个字。它的标题和介绍段落清晰地说明了测试数据的结构,足以让读者不需要回到数据中去了解规则。而下方那些例子则使之变得实际可测,并解释了边缘情况下的行为。并且,它聚焦在免费送货的有效性的这个非常特殊的规则上,没有解释要如何购买这些书,而仅仅只是专注于可用的交付机制是什么,也没有尝试谈论任何实现的细节。
这里也有一个非常糟糕的案例(取自于旧的FitNesse用户指南):

这个测试写得如此糟糕,以至于它某种意义上反而成为了一个很好的例子,用来说明当人们对写好测试漠不关心时,会发生什么。
首先,虽然它有一个标题,和一些围绕表格的说明文字,看起来像是解释发生了什么,但是结果差强人意。为什么说这个测试简单?工资单检查到底检查什么?在“自解释”的石蕊试验中,它彻底失败了。(译注:石蕊试验是利用石蕊检验酸碱度的古老检验方式。现在经常被用于比喻一种立见分晓的检验方法。)
其次,这个测试到底核查了什么完全不清楚。我们不得不回退。它似乎是在验证支票是以唯一的数字打印的,这个数字是从系统中可配置的下一个可用的数字开始。也似乎是在校验每张支票上所打印的数据。而且每个员工打印一张支票(稍后再回到这里)。
这里有很多看似偶然的复杂性——名称和地址这两项数据,除了在建立员工之外,整个测试中的任何地方都没有使用过。还有一些与业务规则完全无关的数据库编号,用于匹配员工和工资检查器。
工资检查器很显然只是为了测试而造的。没有哪个公司会派一身Clouseau装备的Peter Sellers(译注:作者这里的引用来自于经典电影粉红豹系列,Peter Sellers在片中长期扮演了脍炙人口的角色Clouseau检察官。)在那儿一张张的检查支票。如果你有大量的员工,不得不打印支票,你当然不会想要手动检查。那么这正是这个测试的关键。
在测试的断言部分还有一个非常有趣的空白单元格问题,以及两个看似无关联的工资检查表。FitNesse的空白单元格用于打印测试结果进行调试和故障排除,但是不检查任何内容。所以这是一个必须要人工检查的自动化测试——这几乎推翻了自动化的目的。在测试中,空白格通常是不稳定性的一个迹象(稍后将更详细说明这点),它们往往是一个信号,说明你漏了些什么——要么测错了地方,要么就是缺少某个规则,使得整个系统过程可重复并且可测试。
这种语言是不一致的,这使得一开始很难在输入和输出之间建立连接。最下面表格中的1001值是什么东西?表头告诉我们这是一个数字——谢天谢地,我以为那是一根香肠。上面的表格中有一个“支票号码”,但是是什么样的支票号码?这两件事情之间有什么关联?
所以这个测试写的真的是一塌糊涂。
假设地址信息存在是因为打印的支票是结算清单的一部分,有了地址信息,结算清单就可以进行自动化的信封包装,这个测试还是至少漏查了一件非常重要的事情:那就是对的人拿到了对的工资金额。如果第一个人得到了两张支票,这条测试会愉快地通过。如果两个人互相拿到了对方的薪水,这条测试同样也会通过。如果印在支票上的日期是在遥远将来的某一天,远到我们的员工可能来不及兑现,这条测试照样还是可以通过。这些单元格空白的原因还隐藏着另一个规则:支票产生的时间顺序。这一点也没有给出任何说明。所以,这种功能缺口的技术修补方案,就是创建一个带给我们大量假阳性结果的测试。
这个测试是要检查一件事还是多件事情?没有上下文信息,我们很难下结论。如果打印支票的系统还有其他的用途,我会提出一个事实,那就是支票号码是唯一的,并且是从一个可配置的数字开始到每一个单独的页面。而即便我们只是用其来打印工资支票,这依然有可能只是一件事情(工资支票打印)的某一部分。
现在,让我们来清理一下。我们试着回溯,并且删掉所有附带的东西。首先,起一个很好的描述性标题,例如“工资支票打印”,然后,添加一个段落来解释测试结构。
一张支票上有收款人姓名,金额和支付日期。支票本身并没有名字和工资。如果支票打印在结算清单上,那么它也会有一个地址,用于自动信封包装。一个名字和地址的组合应该足够让我们将员工与他的支票匹配起来——我们真的不需要数据库的编号信息。通过商定的排序规则,我们可以让整个系统变得更加可测试——不论这个规则是什么,例如,按字母顺序排序。
让我们将场景拉到测试的开始。我们的背景是工资日期、下一个可用的支票号码、以及员工的工资数据。让我们明确阐述一下每个数字分别是什么,这样以后的读者就不用再自己想办法弄清楚。我们还可以让这个区块视觉上突显出来,以表示它是关于上下文的描述。
需要启动的操作并不一定要列在测试中。一次工资的核算运行可以由检查工资单结果的表进行隐式执行。这个例子聚焦的是什么需要被测试,而不是怎么被测试。这里没有必要用一个单独的步骤来说“下一步我们付钱”。
同样,我们也可以将工资检查器重新命名为更好理解的内容。因为我们希望以后不论是谁来执行这个自动化的过程,都能够确保检查了所有打印出来的支票,所以我们把它放在表格标题当中。不然,有人可能会使用子集进行匹配,导致系统打印每张支票两次,而我们却毫不知情。
这是整理过后的版本。
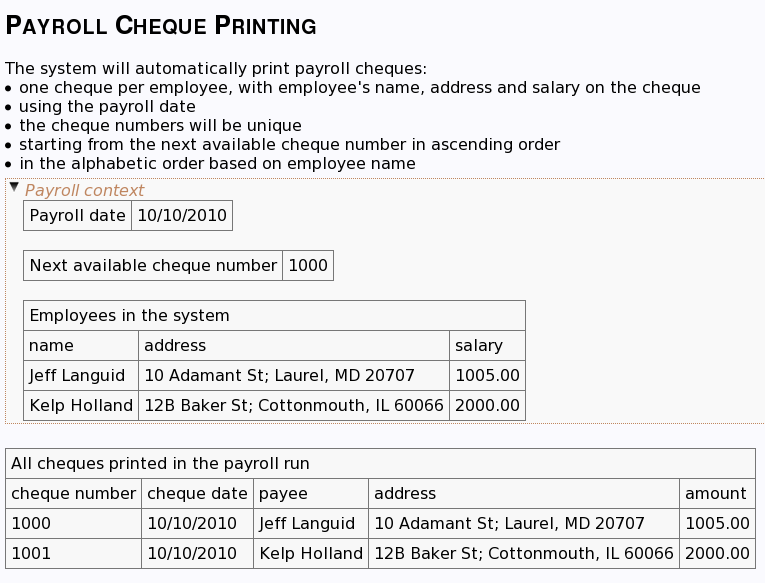
没有了那些附加的东西,测试变得更容易理解了。那么重点来了。当我们看到这样的测试,没有数据库编号,没有所有不必要的杂乱,我们有了一个非常干净的画面,来回答问题“我们是否还漏了什么?”。有哪些边缘情况可能会破坏这个测试?我们倒不需要在此验证员工数据的有效性,系统的其他部分会完成这个任务。但是,有没有任何一种有效的员工数据可以成为这个测试案例的临界值?我们是不是可以通过数字游戏将结果变得不合逻辑?
有一个很明显的答案——如果员工的工资是0,会发生什么?还是照旧打印支票么?规则里提到的是“每个员工一张支票”——所以那些已经被解雇多年的员工,即使他们已经不再领取工资,还是会收到打印的支票,只不过金额是0而已。如此,我们可以与业务部门展开一次讨论,看是否需要强化一下规则,确保在不必要的情况下,没有支票产生。
FitNesse因为这些残破不堪的测试案例而声名狼藉。Concordion(译注:Concordion是一种验收测试的框架)由此应运而生。最近的工作坊当中,也有一些人提出使用Given-When-Then结构的Cucumber能够更好的预防这些问题的产生。我不这么认为。这跟工具无关——人们有可能使用任何工具来进行这种糟糕的测试设计,同样,他们也可以使用FitNesse做出又好又干净的测试。我认为,指出FitNesse的基础案例如此糟糕的事实,这于事无补,问题的关键不在于工具,而在于我们所付出的过程和精力,必须要让测试变得容易理解。有趣的是,让测试变得干净漂亮花不了太多精力,但是它带来的价值却远远不止如此。